O padrão Unicode é um esquema universal de codificação de caracteres para caracteres e texto escritos. Ele define um conjunto de caracteres com muita exatidão da mesma forma que o faz para um pequeno número de codificações. Ele define uma forma consistente de codificar texto multilíngüe, o que permite a troca de dados de texto internacionalmente e cria a base para software global.
Dois dos esquemas de codificação fornecidos pelo Unicode são UTF-16 e UTF-8.
O esquema de codificação padrão é o UTF-16, um formato de codificação de 16 bits. Ele é um subconjunto do UTF-16 que usa dois bytes para representar um caractere. O UCS-2 é geralmente aceito como a página de códigos universal capaz de representar todos os caracteres necessários de todas as páginas de código de byte simples e duplo byte existentes. Ele está registrado na IBM como página de códigos 1200.
O outro formato de codificação do Unicode é o UTF-8, que é orientado por bytes e foi planejado para facilitar o uso com sistemas baseados em ASCII. O UTF-8 usa um número variável de bytes (normalmente 1-3, às vezes 4) para armazenar cada caractere. Os caracteres ASCII invariáveis são armazenados como bytes simples. Todos os outros caracteres são armazenados utilizando múltiplos bytes. Em geral, os dados do UTF-8 podem ser tratados como dados ASCII estendidos pelo código que não foi designado para páginas de código de múltiplos bytes. Ele está registrado na IBM como página de códigos 1208.
É importante que os aplicativos levem em conta os requisitos dos dados conforme eles são convertidos entre a página de códigos local, UCS-2 e UTF-8. Por exemplo, 20 caracteres precisarão de exatamente 40 bytes no UCS-2 e algo entre 20 e 60 bytes no UTF-8, dependendo da página de códigos original e do caractere usado.
Um DB2 Universal Database para Unix, Windows ou OS/2 criado especificando um conjunto de códigos UTF-8 pode ser utilizado para armazenar dados nos formatos UCS-2 e UTF-8. Tal banco de dados é referido como um banco de dados Unicode. Os dados de caracteres SQL são codificados utilizando o UTF-8 e os dados gráficos SQL são codificados utilizando o UCS-2. Isso significa que os caracteres MBCS, incluindo os caracteres de byte único e de byte duplo, são armazenados em colunas de caracteres, e os caracteres DBCS são armazenados em colunas gráficas.
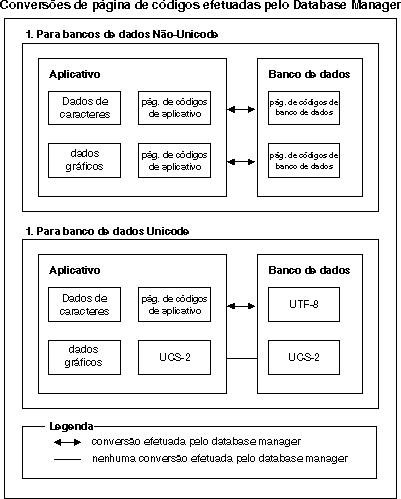
A página de códigos de um aplicativo pode não corresponder à página de códigos que o DB2 usa para armazenar dados. Em um banco de dados não-Unicode, quando as páginas de código não são iguais, o gerenciador de banco de dados converte dados de caractere e gráficos (DBCS puro) que são transferidos entre cliente e servidor. Em um banco de dados Unicode, a conversão de dados de caractere entre a página de códigos do cliente e o UTF-8 é automaticamente executada pelo gerenciador de banco de dados, mas todos os dados gráficos (UCS20 são passados sem qualquer conversão entre o cliente e o servidor.
Figura 1. Conversões de Página de Códigos Executadas pelo Database Manager
Notas:
É possível que um aplicativo especifique uma página de códigos UTF-8, indicando que enviará e receberá todos os dados gráficos em UCS-2 e dados de caractere em UTF-8. Essa página de códigos de aplicativo é suportada somente para bancos de dados Unicode.
Outros pontos a considerar ao usar o Unicode:
CREATE DATABASE unidb USING CODESET UTF-8 TERRITORY US
db2set DB2CODEPAGE=1208
SELECT * FROM mytable WHERE mychar = 'utf-8 data'
AND mygraphic = G'ucs-2 data'
Estas notas sobre o release incluem atualizações para as seguintes informações sobre como utilizar o Unicode com o DB2 Versão 7.1:
Capítulo 3. Elementos de Linguagem
Capítulo 4. Funções
Capítulo 6. Instruções SQL
Capítulo 3. Utilizando Recursos Avançados
Apêndice C. DB2 CLI e ODBC
Para obter mais informações sobre como utilizar o Unicode com o DB2, consulte a publicação Administration Guide, apêndice NLS (National Language Support): "Suporte ao Unicode no DB2 UDB".