The Unicode standard is a universal character encoding scheme for written characters and text. It defines a character set very precisely, as well as a small number of encodings for it. It defines a consistent way of encoding multilingual text that enables the exchange of text data internationally and creates the foundation for global software.
Two of the encoding schemes provided by Unicode are UTF-16 and UTF-8.
The default encoding scheme is UTF-16, which is a 16-bit encoding format. UCS-2 is a subset of UTF-16 which uses two bytes to represent a character. UCS-2 is generally accepted as the universal code page capable of representing all the necessary characters from all existing single and double byte code pages. UCS-2 is registered in IBM as code page 1200.
The other Unicode encoding format is UTF-8, which is byte-oriented and has been designed for ease of use with existing ASCII-based systems. UTF-8 uses a varying number of bytes (usually 1-3, sometimes 4) to store each character. The invariant ASCII characters are stored as single bytes. All other characters are stored using multiple bytes. In general, UTF-8 data can be treated as extended ASCII data by code that was not designed for multi-byte code pages. UTF-8 is registered in IBM as code page 1208.
It is important that applications take into account the requirements of data as it is converted between the local code page, UCS-2 and UTF-8. For example, 20 characters will require exactly 40 bytes in UCS-2 and somewhere between 20 and 60 bytes in UTF-8, depending on the original code page and the characters used.
A DB2 Universal database for Unix, Windows, or OS/2 created specifying a code set of UTF-8 can be used to store data in both UCS-2 and UTF-8 formats. Such a database is referred to as a Unicode database. SQL character data is encoded using UTF-8 and SQL graphic data is encoded using UCS-2. This means that MBCS characters, including both single-byte and double-byte characters, are stored in character columns, and DBCS characters are stored in graphic columns.
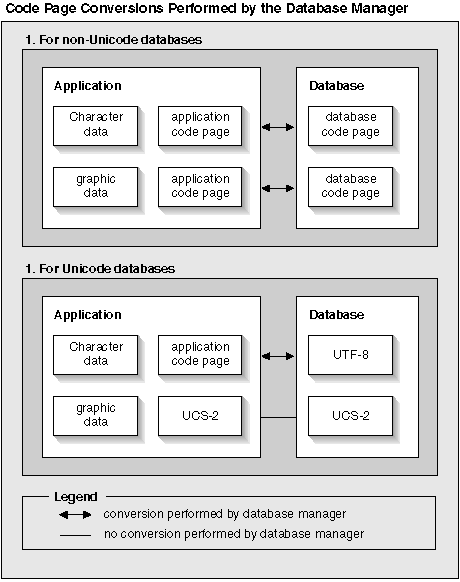
The code page of an application may not match the code page that DB2 uses to store data. In a non-Unicode database, when the code pages are not the same, the database manager converts character and graphic (pure DBCS) data that is transferred between client and server. In a Unicode database, the conversion of character data between the client code page and UTF-8 is automatically performed by the database manager, but all graphic (UCS-2) data is passed without any conversion between the client and the server.
Figure 1. Code Page Conversions Performed by the Database Manager
Notes:
It is possible for an application to specify a UTF-8 code page, indicating that it will send and receive all graphic data in UCS-2 and character data in UTF-8. This application code page is only supported for Unicode databases.
Other points to consider when using Unicode:
CREATE DATABASE unidb USING CODESET UTF-8 TERRITORY US
db2set DB2CODEPAGE=1208
SELECT * FROM mytable WHERE mychar = 'utf-8 data'
AND mygraphic = G'ucs-2 data'
These release notes include updates to the following information on using Unicode with DB2 Version 7.1:
Chapter 3. Language Elements
Chapter 4. Functions
|Chapter 6. SQL Statements
Chapter 3. Using Advanced Features
Appendix C. DB2 CLI and ODBC
For more information on using Unicode with DB2 refer to the Administration Guide, National Language Support (NLS) appendix: "Unicode Support in DB2 UDB".