
You can build on the typical replication configurations to come up with replication models that meet your specific needs. This section discusses examples of some common business needs and the DB2 replication solution that addresses those needs. Design issues that are unique to each replication solution are described.
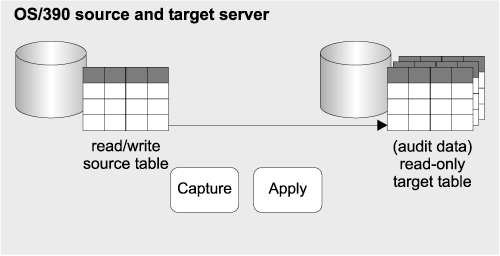
Requirements: A customer in a DB2-IMS Transaction Manager (TM) environment generates audit data by writing audit information to the IMS log. New applications access DB2 through DRDA, bypassing IMS TM completely. The customer needs to track all changes to relational tables for auditing purposes to determine which users made particular changes to the data.
Replication solution: The Capture and Apply programs for DB2 DataPropagator are used to capture and store the DB2 for OS/390 changes in target tables (see Figure 6).
|
Design highlights: Both the before-image and the after-image values of each row are captured and stored. The authorization ID of the person who changed the data is also stored in the audit tables. All of this information is captured from the DB2 for OS/390 log.
Requirements: A large retail chain has almost 500 stores around the country, each of which gathers purchase details through an electronic point of sale (EPOS) system. Each store keeps its data in local databases on DB2 for AIX. They transfer the data nightly to a central DB2 for OS/390 site using a pre-existing file-transfer process from the EPOS terminals. The company wants to enhance the data at the central site and then distribute it to each of the stores and to some regional offices.
Replication solution: Data changes at each retail store are captured and saved by the Capture program on DB2 for AIX (see Figure 7). The Apply program on DB2 for OS/390 consolidates the data from all stores, summarizes the data, and distributes the summarized, consolidated data to regional offices and stores. Employees at each store can see the local trends and their performance against that of other outlets in the region. Regional managers are able to plan their marketing and distribution strategies by using the information to help set objectives for the individual stores.
Figure 7. Consolidating data from distributed databases
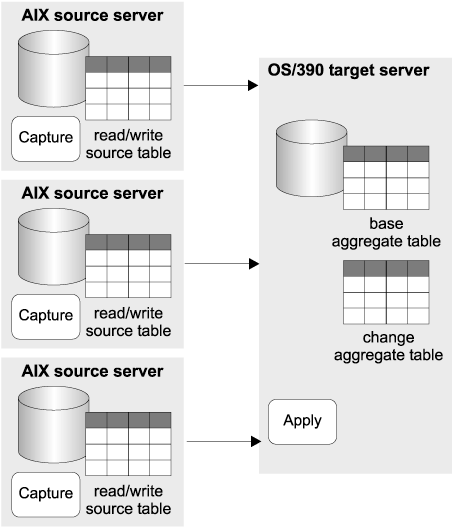 |
Design highlights: The Apply program uses base aggregate and change aggregate tables to summarize the consolidated store data. The base aggregate tables summarize the contents of the source files. The change aggregate tables summarize the results of the changes made between each target refresh that is performed by the Apply program.
Requirements: A small bank installed several new Windows NT client/server applications in its 85 branches. A major source of data for the new applications is the customer and financial reference data, which is derived and held at a host site in two operational systems, one on DB2 for OS/390 and the other on DB2 for AIX. If branches accessed the data directly from the host site, network traffic would be congested and the availability of the production data could be affected.
Replication solution: To minimize the network traffic, a local copy of the database is maintained at each branch (see Figure 8). Therefore, each branch is a target server. Changes are captured from DB2 for OS/390 and DB2 for AIX, condensed in control tables on DB2 for AIX, and replicated to the branches overnight.
Figure 8. Distributing data to remote sites
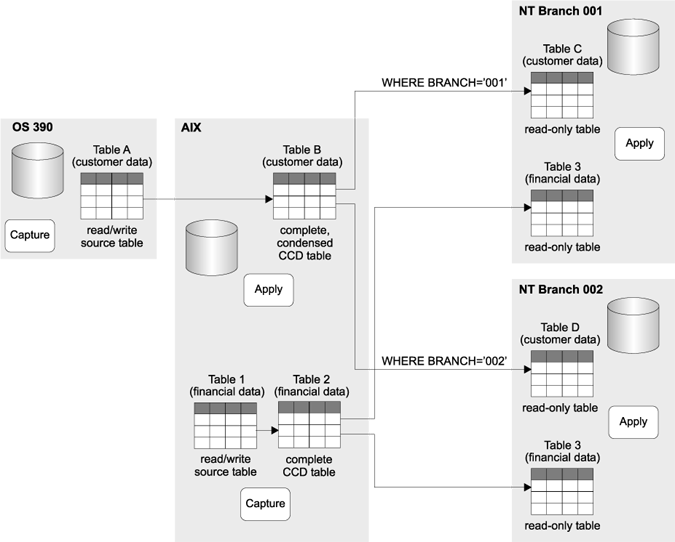 |
Design highlights: One Apply program resides on AIX and replicates from DB2 for OS/390 and DB2 for AIX. There is one subscription set for replicating from DB2 for OS/390 to DB2 for AIX and one for replicating from DB2 for AIX to DB2 for AIX.
An Apply program also resides on the target servers at each branch. The Apply program on the source server runs separately from the Apply programs at the target servers. The Apply program at each of the branches replicates from the control tables on DB2 for AIX at the host site. Each of the Apply programs on the target servers has a subscription set for replicating from the host site to its local database. Each branch gets all of the financial data but only some of the customer data. WHERE clauses are used to ensure that each branch gets the records that pertain to their own customers only.
The Capture and Apply programs maintain complete, condensed CCD tables in DB2 for AIX. The administrator chose a condensed CCD table because that type of staging table contains only the most recent change made to a row, so network traffic is reduced during replication.
When the subscription sets were created for each branch, the administrator put the control server on the Windows NT server. If the administrator had put the control server on DB2 for AIX, the Apply program from each Windows NT server would need to connect to the host site over the network to read and update the control information about the subscription set, and to detect changes to its control information.
Requirements: A large financial institution wants to improve the flow of information from two legacy operational systems to its OS/2-based branches. It wants to provide more accurate and timely data to help loan-application research and to detect credit-card fraud. The data for loan applications is in DB2 for OS/390, and the credit card details are in an IMS system. Previous attempts to copy the legacy data consisted of an unworkable mixture of ad-hoc reports and file transfer techniques.
Replication solution: DataPropagator NonRelational is used to capture and save the changes to IMS data into CCD tables in DB2 for OS/390 (see Figure 9). The DB2 DataPropagator Capture program is used to capture and save the changes to DB2 for OS/390 data. The data that is saved is historical--it records every change made. The Apply program runs at the branches and uses the historical data from IMS and DB2 for OS/390 to maintain DB2 for OS/2 tables.
Figure 9. Distributing IMS data to relational databases
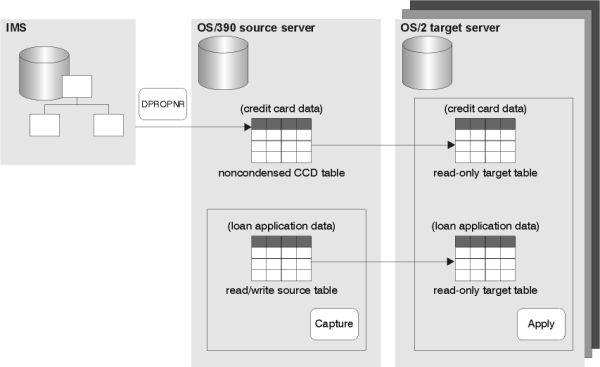 |
Design highlights: DataPropagator NonRelational captures changes from the IMS log and creates a noncondensed CCD table in DB2 DataPropagator format on the OS/390 source server. DB2 DataPropagator uses this CCD table as a replication source. The Capture program on the OS/390 server captures information from the local tables that contain the credit-card and loan-application data. The Apply program on the OS/2 target server pulls the change data to the target tables.
Requirements: An international bank wants to keep its system online 24 hours a day. Currently the system is online 23 hours 45 minutes a day. Every day the bank stops the system to quiesce it for a batch application, which requires exactly one day's worth of data. During the 15 minutes when the system is down, the required tables are extracted. After the extraction, the system is made available for the next financial day.
Replication solution: Data changes made during the day are captured and replicated to CCD tables (see Figure 10). The batch application was modified to process the changes in the CCD tables instead of the table extracts. The online system does not need to be stopped to provide consistent data for the batch application.
Figure 10. Batch application using replicated data
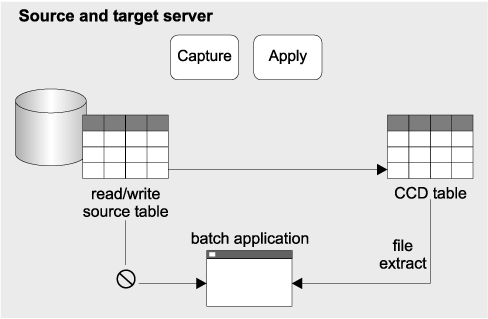 |
Design highlights: The CCD table includes a timestamp that is used to identify the changes made during a time period (in this case, one day).
Requirements: A financial institution needs to replicate updates from its customer information database on DB2 for AS/400 to a decision support system that is also on DB2 for AS/400. Historical data about updates must be saved and stored with no code changes to production applications and no impact to the performance of those applications.
Replication solution: Updates are captured from the key operational tables and, on an hourly basis, replicated to CCD tables in the decision support system (see Figure 11).
Figure 11. Replicating operational data to decision support systems
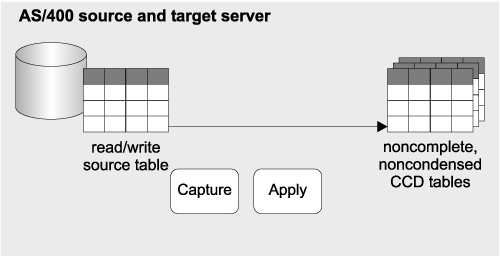 |
Design highlights: The Capture and Apply programs maintain noncomplete, noncondensed CCD tables. Noncondensed CCD tables are used because they record all changes that are made to the customer information database. Furthermore, noncomplete CCD tables are used because the financial institution does not want to record the original contents of the source, it wants only the changes.
The Capture and Apply programs are given job priorities such that replication does not impact production CPU resources. The decision support system could be implemented just as easily on any of the supported target platforms and could still be ported to other platforms, if required.
Requirements: A financial institution has hundreds of agents at several branches who must fill in online forms to set up and modify client accounts. The agents base the quotation rates on information that was generated at the head office and sent to the branch. The agents send reports back to the head office, and the accounts are finalized only after the information is verified at the head office. The agents would be more productive if they had access to up-to-date data, without the network problems of accessing the central database directly.
Replication solution: A special type of target table, called a replica, is used to set up circular subscriptions (see Figure 12). Changes to the replica are replicated back to the primary replication source, which is a user table. An update that is made at one location is reflected in the databases at other locations. Agents have the current information that they need to finalize accounts while meeting with the client, and the head office has the new business data generated that day.
Figure 12. Update-anywhere replication example
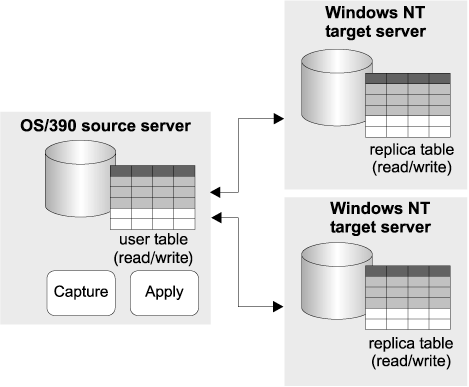 |
Design highlights: The primary replication source is a user table. It contains the most up-to-date information.
This type of replication works best when transaction conflicts between the central database and the updatable copies can be avoided, such as when copies can update only key ranges at specific sites, or when sites can make updates only during certain time periods.
DB2 DataPropagator detects conflicts that occur when the same row is updated on the host system and on an agent's system and neither change has been replicated. If an agent made updates that are in conflict, these updates are discarded during replication to ensure data integrity. The transaction containing the conflict and all captured transactions that are found that are dependent on the conflicting transaction are backed out.
Requirements: An insurance company wants to equip its sales agents, who rarely visit the company's home office, with a set of offers to attract both new and existing customers--special introductory offers and personalized packages. Much of the time, the agents' computers will not be connected to the home office. When they connect to the home office, they need to get any updated information from the central database. Managing the potential backlog of changes can be an issue.
Replication solution: The sales force is supplied with laptop computers running DB2 Universal Database Satellite Edition. As a sales campaign is launched, each agent downloads the customer profiles and history, as well as the latest product offers. DB2 replication also solves the problem of keeping the information up to date. Only new and changed data rows are copied across the network.
Design highlights: DB2 Universal Database Satellite Edition is used because it meets the replication requirements and can be administered by a central administrator. An administrator at the home office sets up the replication environment, tests it, and copies it to the occasionally connected systems. The administrator also provides user IDs and passwords to the agents in the field so that they can connect to the server at the home office from their laptop computers. While they are logged on, the agents can synchronize the information on their laptop computer with the information at the source server by simply pressing a button.