Microsoft
Microsoft Cluster Service (MSCS) System Validation Test Plan For Windows 2000
Version 1.7 . November 4th 1999
This document describes the test plan for MSCS system validation, including the hardware and software requirements. MSCS is the high-availability clustering feature of Microsoft Windows NT Server 4.0 Enterprise Edition, Microsoft Windows 2000 Advanced Server, and Microsoft Windows 2000 Datacenter Server.
For Windows NT 4.0 Cluster Testing, see Wolfpack Clustering White Paper - Windows 2000.
Also see the Clustering Readme.
Contents
Introduction....................................................................................................................................................................... 4
Definitions................................................................................................................................................................... 4
Obtaining an MSCS
System HCT CD and Self-Test Kit...................................................................................... 5
Checking the Cluster
HCL on the Web................................................................................................................... 5
Windows 2000 RC 3................................................................................................................................................... 5
Systems Requirements
and Configurations................................................................................................................. 7
Server Requirements
for an MSCS System............................................................................................................ 7
Network requirements
for running tests................................................................................................................. 7
Client Requirements
for an MSCS System............................................................................................................. 8
MSCS Configuration
Components.......................................................................................................................... 8
Setup Instructions for
Validation Testing.................................................................................................................. 11
Phase 1 Testing (24
hours)............................................................................................................................................ 12
Shared Storage Bus
Testing................................................................................................................................... 13
Phase 2 Testing .
Validate 1 Node (24 hours)........................................................................................................... 14
Phase 3 Testing .
Validate Move Group 2 Node (12 hours).................................................................................... 14
Phase 4 Testing .
Validate Crash 2 Node (12 hours)................................................................................................ 15
Phase 5 Testing .
Validate 2 Node (24 hours)........................................................................................................... 15
Running Optional Tests
in Validation testing (Phase 2-5)....................................................................................... 15
Installing optional
test components for DHCP or WINS................................................................................... 15
Installing optional
test components for FTP....................................................................................................... 16
Installing optional
test components for MSMQ................................................................................................. 16
Client Server Tests......................................................................................................................................................... 17
Setting up and running
client/server tests........................................................................................................... 18
Troubleshooting the
failures.................................................................................................................................. 21
Interpreting the log.................................................................................................................................................. 22
File I/O Testing Using
an File Share...................................................................................................................... 23
IIS Testing................................................................................................................................................................. 25
Print Server Testing................................................................................................................................................. 26
WINS
Testing (optional test)................................................................................................................................. 26
DHCP Testing(optional test).................................................................................................................................. 27
COM+ (MSDTC) Testing(optional test)............................................................................................................... 27
Causing Cluster
Failovers During Client-Server Tests....................................................................................... 28
Failover Program............................................................................................................................................................. 28
Interpreting the
failover log.................................................................................................................................... 29
Trouble shooting
Failover...................................................................................................................................... 29
Simultaneous Reboot
Test (optional, no logs required)........................................................................................... 30
How to Submit results
to WHQL................................................................................................................................. 30
What to do if tests
fail, but you think it is a test bug......................................................................................... 30
How to Return Log
results...................................................................................................................................... 31
Cluster description on
the HCL.............................................................................................................................. 31
Contact Information................................................................................................................................................. 31
This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.
This documentation is an early release of the final product documentation. It is meant to accompany software that is still in development. Some of the information in this documentation may be inaccurate or may not be an accurate representation of the functionality of the final retail product. Microsoft assumes no responsibility for any damages that might occur either directly or indirectly from these inaccuracies.
Microsoft Corporation may have patents or pending patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document. The furnishing of this document does not give you any license to the patents, trademarks, copyrights, or other intellectual property rights except as expressly provided in any written license agreement from Microsoft Corporation.
Microsoft does not make any representation or warranty regarding specifications in this document or any product or item developed based on these specifications. Microsoft disclaims all express and implied warranties, including but not limited to the implied warranties or merchantability, fitness for a particular purpose, and freedom from infringement. Without limiting the generality of the foregoing, Microsoft does not make any warranty of any kind that any item developed based on these specifications, or any portion of a specification, will not infringe any copyright, patent, trade secret, or other intellectual property right of any person or entity in any country. It is your responsibility to seek licenses for such intellectual property rights where appropriate. Microsoft shall not be liable for any damages arising out of or in connection with the use of these specifications, including liability for lost profit, business interruption, or any other damages whatsoever. Some states do not allow the exclusion or limitation of liability or consequential or incidental damages; the above limitation may not apply to you.
ActiveMovie, ActiveX, BackOffice, Developer Studio, Direct3D, DirectDraw, DirectInput, DirectPlay, DirectSound, DirectVideo, DirectX, Microsoft, NetMeeting, NetShow, Visual Basic, Win32, Windows, Windows NT and Windows 2000 are trademarks or registered trademarks of Microsoft Corporation in the United States and/or other countries. Other product and company names mentioned herein may be the trademarks of their respective owners.
© 1997, 1998, 1999 Microsoft Corporation. All rights reserved.
Introduction
This test kit is
intended for use on Windows 2000 Advanced Server RC 3. For this release please do not run the
validation tests for Windows 2000 Advanced Server RC 3 with clients running
Windows NT 4.0. There are known test
issues that prevent this scenario from working correctly. These problems will be resolved for the
released versions of Windows 2000 Advanced Server and Windows 2000 Datacenter
Server.
This document is the test plan for MSCS system validation. It describes the hardware and software requirements for the validation process. The intended audience is people who are involved in validation of MSCS-based cluster systems and also IHVs who wish to have systems validated. This document does not go into great detail about each specific test. Microsoft has other documents for each test that give specific testing criteria and methodology. This document is in draft form, and several issues have not yet been resolved. Issues that Microsoft is still resolving include:
· How test results will be cataloged. In the final version of the validation process, log files will have to be submitted to Microsoft. Microsoft will review your results and, based on that review, will add your configuration to the Cluster configuration HCL.
· What types of failures will prevent the system from being validated.
· What the final tests will be. Microsoft will probably add more tests to the client-server test list.
The exact step-by-step procedure for running the test is not in this document because the entire test CD is not yet complete. Microsoft will provide this when the CD is completed.
This test plan is not meant for cluster device testing.
The contents of this document are subject to change. Please refer to the most recent HCT CD for MSCS validation and print the latest copy of the MSCS System Validation test plan to obtain an update.
Definitions
The following terms are used throughout this document.
MSCS: Microsoft Cluster Service (MSCS) System is the high-availability clustering feature of Microsoft Windows NT Server 4.0 Enterprise Edition, Microsoft Windows 2000 Advanced Server, and Microsoft Windows 2000 Datacenter Server.
HCL: Hardware Compatibility List. The list of hardware components that are validated for the Microsoft® Windows NT, Windows® 95, Windows 98, or Windows 2000 operating systems.
HCT: Hardware Compatibility Tests. The set of tests that are run to perform validation of hardware that will be added to the HCL. An HCT kit is available from Microsoft, as described in the following section.
HW RAID: A RAID that is done with no knowledge of the operating system. As far as Windows NT knows, these RAID sets appear to be a normal physical disk and the RAID operations are all done in hardware.
SW RAID: This is what is meant when using the Windows NT Server Ftdisk driver or Windows 2000 . dynamic disks. to take several physical disks and make one logical fault-tolerant (FT) volume out of them.
WHQL: Windows Hardware Quality Labs. The Microsoft lab that performs the component validation testing for components that must be submitted to Microsoft.
Obtaining an MSCS System HCTCD and Self-Test Kit
Visit http://www.microsoft.com/hwtest/hctcd to obtain an official MSCS self test CD
Windows NT Server 4.0 Enterprise Edition CDs are available by OEM, Select, Retail, and MSDN licenses. Do not contact WHQL for Windows NT Server 4.0 Enterprise Edition CDs.
Checking the Cluster HCL on the Web
Visit the site at:
http://www.microsoft.com/hcl
You can search under Product Category .
Cluster. for the list of all complete cluster configurations for each
vendor.
You can also search categories cluster/raid, cluster/scsi,
and cluster/fiberchannel to see a list of cluster candidate components that can
be used for complete cluster configurations. Please note that no Microsoft product support
service is offered on the basis of cluster candidate component
certification.
Only complete configurations listed under . cluster. are valid
configurations for Microsoft product support services.
Windows 2000 RC 3
Example Configuration
Creating an MSCS cluster requires two PCI-based Intel® Pentium or equivalent . x86. systems configured as described in the following list. For development purposes, any PCI-based x86 system listed on the Windows 2000 HCL can be used as an MSCS cluster node.
1. At least one shared SCSI bus formed by a PCI-based SCSI controller is installed in each system.
· The SCSI IDs of the two controllers on a shared bus must be different. By default, SCSI controllers are assigned ID 7. One must be changed to another value (for example, 6) before they are both connected to the same bus.
· The boot-time SCSI bus reset operation should also be disabled on each controller attached to a shared bus. This option can be disabled using the configuration utilities supplied by the manufacturer. Some SCSI cards may not support this feature though. It will make systems boot faster to disable it but will not prevent the tests from running.
2. At least two external SCSI disks attached to one of the shared buses. Each disk must be formatted for Windows NT file system (NTFS) only. A single partition is recommended on each disk because logical partitions cannot be independently failed over. The same drive letter should be permanently assigned to a given shared disk on each system.
3. At least one disk on each system is not attached to any of the shared buses.
4. Windows 2000 is installed entirely on the nonshared disk(s) of each system. All paging files and system files must be on nonshared disks.
5. At least one shared LAN is for intracluster communication. A single network adapter in each system must be attached to this LAN and configured with the TCP/IP protocol. Each adapter must be assigned an address on the same IP subnet. The intracluster network must use PCI NICs.
6. At
least one shared LAN is for client access to the cluster. A single network
adapter in each system must be attached to this LAN and configured with the
TCP/IP protocol. Each adapter must be assigned an address on the same IP subnet.
Clients can be connected to this LAN by a routed IP network. The same LAN (and
IP subnet) can be used for both intracluster communication and client access.
7. One static TCP/IP address is for the cluster and one is for each resource group that will be created. These addresses will be used by clients to access cluster services. These addresses must be supplied to the MSCS setup and administration programs when resource groups are created.
Figure 1a illustrates a typical MSCS SCSI configuration. Figure 1b illustrates a typical MSCS Fibre Channel configuration.
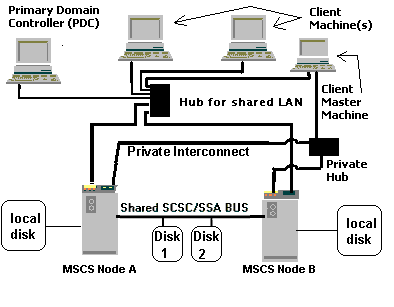
Figure 1a. Standard MSCS configuration using SCSI (or SSA) adapters

Figure 1b.
Standard MSCS Configuration using Fibre channel adapters
Systems Requirements and Configurations
This section presents the system configuration criteria for an MSCS system. Note that all components in a cluster system must be validated to run on Windows 2000 and be on the HCL before they will be considered for MSCS-specific testing. Components that are not on the HCL must pass HCT tests prior to MSCS testing, because MSCS testing is designed to test MSCS requirements, not general Windows 2000 requirements.
For this type of hardware testing, the HCT kit and BackOffice® testing programs are used. The following lists constitute an MSCS configuration.
Server Requirements for an MSCS System
· 256-MB minimum system memory
· System BIOS and firmware
· Internal drive(s) used to boot each node of the cluster (can be either IDE or SCSI )
· PCI SCSI, Fibre Channel, or RAID controller and drives used for the storage bus (different from the one used for the internal boot drive)
· Network card(s) used for intracluster and client communications.
No ISA network card or storage devices should be used in a cluster.
In addition to the minimum system requirements for a cluster, Microsoft will require the following for system validation:
· At least two shared disks on the storage bus (SCSI, Fibre Channel, etc.). These are logical drives that are seen at the Windows 2000 SCSI class driver and can represent many physical drives in some RAID implementations. Microsoft recommends that the number of disks on the shared bus represent a typical customer configuration. The client-server tests will exercise a default maximum of eight shared disks. The default maximum is configurable through the test GUI.
· At least eight client nodes + 1 client master node that can connect to the cluster using a network using TCP/IP. Client requirements are detailed below.
· At least one static IP address per disk on the shared bus. One of these static IP addresses will be used to setup up the cluster virtual server. The remaining static IP. s will be used to setup additional virtual servers for testing. The client-server tests will stress each of these virtual roots. These static IP addresses must be on the same subnet mask as the client machines and also the cluster servers.
· Minimum of at least 250 MB free hard disk space on system drive
It is highly recommended that all disks should be formatted as NTFS. The shared disks in cluster must be formatted as NTFS.
Network requirements for running tests
The phase 2-5 tests will generate a lot of network traffic
doing client/server type of IO. We recommend that all of the client machines
and cluster nodes be on a private network. The cluster nodes may be setup as domain
controllers.
However we find that the best results for this heavy level of stress
testing is to have another server that is always up providing domain
services.
The client nodes, client master node, and the cluster nodes must all be a member of this same domain. We typically have our lab setup to have all machines logged on as the same domain account that has local administrator rights on each node. We use this same account for the cluster service also.
The server nodes will experience very high stress loads with file I/O, IIS queries, and FTP queries. This is by design and is done to simulate what we believe will be the real world customer usage of high-end cluster configurations. The network stress loads however are probably higher than what any customer would utilize under normal circumstances. We recommend that all testing be done on a private network.
Client Requirements for an MSCS System
The client machines will be used to simulate client-server stress against the cluster. The eight required client nodes cannot be used to test more than one cluster at a time. The idea of having eight dedicated clients is that Microsoft can run many tests on each node, simulating many real-world clients. For each cluster you want to test in parallel, you must have a different set of client machines. These clients must meet the following hardware and software requirements:
· If MSCS certification is being done with Windows NT Server 4.0 Enterprise Edition, each client must be on the Windows 2000 HCL and running Windows NT Workstation 4.0. If MSCS certification is being done with Windows 2000 Advanced Server or Windows 2000 Datacenter Server, each client must be on the Windows 2000 HCL and running Windows 2000 Professional.
· Each client should have at least 128 MB of memory
· Each client should be at least a Pentium II -class or better machine. Microsoft recommends a client mix as close to your typical customers. use as possible. Microsoft uses six 128-MB Pentium II machines, and two high-end workstations.
· Each client must have an HCL network card installed.
· Each client must be able to communicate with the cluster over TCP/IP.
· The clients must be in the same domain as the cluster nodes.
An additional client will also be needed as the client monitoring system (also called the . client master. or . client monitor. below.) This client should be separate from the clients used for client-server stress testing. It has the same hardware requirements as other client machines except that it should be running Windows 2000 Server or Windows 2000 Advanced Server and it should have at least 256 MB of memory plus two free serial ports. The client master must also be able to communicate through TCP/IP with all of the test systems and it should be able to handle minimum 100 concurrent network sessions. This includes the eight clients as well as the cluster nodes. The client master is used to:
· Run the MSCS cluster administrator to monitor the status of the cluster.
· Provide a share point to start up the client tests on the other clients.
· Cause automated failover testing in testing Phase 2-5.
· Serve as the kernel debugger for each server node. This requires a free serial port for each cluster node to set up the kernel debugger. Please see documentation in the Windows 2000 device driver kit (DDK) for setting up a kernel debugger.
MSCS Configuration Components
An MSCS configuration consists of three main components.
· Two or more servers.
· A shared disk configuration using fibre or multi-initiator SCSI.
· The . interconnect. network interface card in each server used for intracluster communications.
All three must be on the appropriate Microsoft HCL. Microsoft views MSCS requirements as a superset of normal HCL requirements. However, the normal HCL is a starting point for MSCS configurations. MSCS validation is designed primarily to ensure that a given hardware cluster configuration will work with MSCS. The HCT kit is used to ensure proper functionality of hardware with normal one-node Windows NT Server or Windows 2000 Server.
The Cluster configurations listed on the HCL will be a complete configuration as described in the previous section. However, a particular configuration is not a validated MSCS configuration until it has successfully gone through the system validation process, which is described in the rest of this document.
One goal of each configuration should be to eliminate any Single Point of Failure. This can include power failures, SCSI cables coming loose, disk cabinets failing etc. Because MSCS is intended to serve as the foundation for highly available systems, it is recommended (though not required) that configurations minimize or eliminate single-points-of-hardware-failure configurations.
Servers in an MSCS Configuration
The MSCS server requirements are fairly minimal. Microsoft requires the server to have PCI slots because all the shared SCSI adapters that Microsoft has tested are PCI-based controllers. MSCS is designed to work in any x86 (Pentium-class or better) server on the HCL list, including uniprocessor and multiprocessor machines. All servers must go through normal HCL testing before any MSCS configuration testing and must be on the appropriate HCL list.
Shared Storage Bus in an MSCS Configuration
The shared SCSI bus is probably the most sensitive part of an MSCS configuration. There are four components that potentially make up the shared SCSI bus, although not all four are required for any given configuration. The components are:
· Fibre Channel Adapter or SCSI Adapter
· RAID Controller (SCSI or Fibre Channel)
· RAID System (SCSI or Fibre Channel)
All of these components must be on their respective HCL before any MSCS testing will be done. Microsoft has categories on the HCL for cluster candidate components of these types. Any of these components that are already on the HCL can be submitted to Microsoft for cluster candidate component testing. If the component is not on the HCL, then both normal HCL testing and cluster candidate component testing can be done with the same submission. They will be tested in a variety of configurations to help ensure that any IHV will be able to use them in an MSCS configuration.
For information on submitting storage components for cluster candidate component validation, please see the web site at http://www.microsoft.com/hwtest/hwtest.htm. There is also an e-mail alias for questions about WHQL testing at whqlraid@microsoft.com.

Figure 2. MSCS component and system certification process
Interconnect Cards in an MSCS Configuration
Interconnect cards are what MSCS uses to communicate between the nodes of a cluster. This network needs to be high-speed and highly reliable. The most important aspects of this are the speed at which packets can be sent over the network, the number of dropped packets, and the reliability.
Interconnect cards must pass normal certification for Network Interface Cards.
NIC Teaming is not supported on Windows NT 4.0 Clustering as well as Windows 2000 clustering.
How to configure private cluster networks
This is one of the ways you can configure the private networks. Connect all the private networks to the hub. Assign the static IP Address of 10.1.0.1 with a subnet mask of 255.255.0.0 for the cluster node1. For node2 assign 10.1.0.2 with subnet mask of 255.255.0.0. And so on. To set the IP Address go to Start Menu->Settings->Network and Dial-up Connections. Right click on the private connection, select Properties. Select the properties for Internet Protocol (TCP/IP). Choose . Use the following IP Address. and specify the above mentioned IP Addresses.
Changes That Constitute a Different Cluster Configuration
As shown in Figure 2, the final cluster configuration consists of three main components. Any major change to these components will result in a new cluster configuration and therefore will require new validation testing. Defining configurations in this way ensures that the end product will work correctly when MSCS is installed. Major changes are defined as the following:
· Changing the server used in the configuration. We determine a different server if there is a separate entry in the HCL for that server.
· Changing the server from a uniprocessor to a multiprocessor model.
· Changing the server from a multiprocessor to a uniprocessor model.
· Changing or adding a SCSI HBA of a different type than previously validated.
· Changing or adding a SCSI RAID HBA of a different type than previously validated.
· Changing or adding a SCSI HW RAID box of a different type than previously validated.
Changes That Do Not Constitute a Different Cluster Configuration
Microsoft wants to provide as much flexibility as possible for system vendors to build cluster configurations while at the same time ensuring that the configurations will work correctly. Changes to configurations that don. t have a major impact on the operability of MSCS will not constitute a new configuration.
Depending on the results of the system validation testing, Microsoft can change the process to allow more or fewer variations within a configuration. The following changes are believed to have no major impact upon MSCS and therefore do not constitute a new configuration. Therefore, when making these changes, no new validation needs to be done. However, it is recommended that all systems be tested periodically. Non-major changes are defined as the following:
· Changing the Raid level used in HW raid. Going from all Raid 1 sets to all Raid 10 sets for example doesn. t make it a new configuration. When the SCSI devices are tested at Microsoft they will be configured and tested in all different configurations.
· Changing the number of processors in a multiprocessor server. (example 2->4 or 4->2)
· Changing the network card used for client access as long as this new card is in on the HCL.
· Changing the interconnect card. As long as the new card is a PCI 100% compliant NDIS card and on the HCL.
· Changing the internal bus used to boot the system.
· Adding more memory to the server.
· Changing the speed of the processors in the server.
· Adding another SCSI HBA of the same type, as long as the storage solution on that new bus is the same as the original tested configuration.
· Adding another SCSI RAID HBA of the same type, as long as the storage solution on that new bus is the same as the original tested configuration.
· Adding another SCSI HW RAID box of the same type, as long as that RAID box is on a bus with a SCSI HBA previously in the configuration.
· Adding more disks to a configuration.
· Any changes to devices that are not on the cluster candidate component HCL, such as internal CD-ROM drives, tape drives, video cards, and so on.
Setup Instructions for Validation Testing
This section summarizes setup for both the hardware and software. The setup order corresponds directly to how the tests will be run, and should be followed precisely.
Before Phase 1:
1. Set up the hardware as shown in Figure 1 earlier in this document.
2. Install the same operating system on both servers in the cluster: either Windows NT Server 4.0 Enterprise Edition and the latest Windows NT service pack or Windows 2000 Advanced Server and the latest Windows 2000 service pack.
3. Make sure that the NodeA node can see the NodeB node on the network.
4. Run Phase 1 tests.
5. Ping the Cluster IP Address from the master client machine and client machines. If ping fails, you need to fix the network connectivity between cluster nodes and clients as well client master machine.
After Phase 1 test completes.
1. Reboot NodeA, and then turn off NodeB.
2. Partition each drive on the shared bus for one partition. Create one partition for each shared drive.
3. Format each drive with NTFS.
4. Install the MSCS software on NodeA.
5. Turn on NodeB.
6. Join NodeB to NodeA, forming a cluster.
7. (Optional) Install optional test components for FTP, DHCP, WINS or MSMQ. See directions below.
8. Turn off NodeB.
9. Run the Phase 2 - Validate 1 Node Cluster test from the HCT kit (see instructions later in this document).
After the Phase 2 test completes.
1. Reboot NodeA.
2. Turn on NodeB.
3. Run the Phase 3- Validate Move 2 Node test from the HCT kit (see instructions later in this document).
After the Phase 3 test completes.
1. Reboot NodeA and NodeB.
2. Run the Phase 4 . Validate Crash 2 Node test from the HCT kit (see instructions later in this document).
After the Phase 4 test completes.
1. Reboot NodeA and NodeB.
2. Run the Phase 5 . Validate 2 Node Cluster test from the HCT kit (see instructions later in this document).
After Phase 5 test completes.
1. Review the optional tests
.
Phase 1 Testing (24 hours)
Phase 1 is designed to stress the hardware of the cluster configuration, as depicted in Figure 1a or Figure 1b, to verify its ability to support MSCS. Currently, Phase 1 testing consists of shared storage bus testing,
During Phase 1 testing, the MSCS software must not be installed. It is not necessary that disks attached to the shared storage bus be formatted with any file system. Phase 1 performs tests that write to the shared disks, any user or file system data previously stored on the disk will be lost. The shared disks will need to be reformatted in order to be mounted after Phase 1. However, the Phase 1 tests rely on the disk signature to identify shared disks, therefore it is necessary that each disk have an unique disk signature.
If the cluster hardware configuration includes a hardware RAID component, the disk arrays must be configured on that component before testing begins. This arrays will be treated as any other disk drive.
Phase 1 testing can be expected to take one day.
Shared Storage Bus Testing
The shared storage bus is an integral part of the cluster. s hardware configuration. This bus may be a SCSI bus as depicted in Figure 1a or a Fibre Channel Fabric or Arbitrated Loop as depicted in Figure 1b. This testing stress the shared storage bus by issuing SCSI commands to the SCSI bus or to the SCSI protocol on the Fibre Channel.
These tests will run on each disk found on the shared storage bus. These tests are broken into two categories:
· Cache Coherency Tests: These tests write a generated test pattern of a random length to blocks on the disk, with the Forced Unit Access (FUA) and Disable Page Out (DPO) bits set. The other initiator will issue a read command, also with the FUA and DPO bits set, and then compare the data in memory. Variations of this test will select the starting block address of the write and read commands to generate random and sequential I/O patterns. Each node will participate in both the . writer. and . reader. roles.
·
Reserve/Release Tests: These
tests will insure that drivers, shared disks, and other SCSI components
correctly implement SCSI Reserve and Release commands, the MSCS shared disk
arbitration relies on this mechanism. One initiator will reserve the disk, commands
issued to the disk from the other initiator should fail with . Reservation
Conflict. status.
These tests also insure that reservations are broken with a bus reset.
To start the test, run on node NodeA:
1. On the . Available Tests. list, click the . Cluster. plus box.
2. Click the . CliSrv. plus box.
3. Select . Cluster N Node Test Client. .
4. Click the . Add. button.
5. Click the Start button to start the test, this will start 2 processes (and 2 command windows). One process is the . Cluster N Node Test Client. , . the other is the Cluster N Node Test Server. .
Then start the test run on node NodeB:
1. On the . Available Tests. list, click the . Cluster. plus box.
2. Click the . CliSrv. box.
3. Select . Cluster N Node Server Test. .
4. Click the Add button.
5. Click the . Cluster\CliSrv\Cluster N Node Test Server. plus box under . Selected Tests. .
6. Double-click the text under the plus box and change Param2 (. Client Name. ) to the name of the computer serving as the test client.
7. Click the OK button.
8. Click the Start button to start the test, this will start 1 process and 1 command window. The process is the Cluster N Node Test Server.
Each process will create a standard Windows NT log file with the results from the test. The . Cluster N Node Test Server. processes create log files named NnodeSim_Server.log, there will be one of these files on each node which participated in the test. The . Cluster N Node Test Client. process creates a log file named NnodeSim_Client.log, there will be one such file created on the node that served as the test client.
From the HCT test manager, you can easily view the results of each test. If the test fails, it will report in the client log why the test failed. If the actual failure happened on the server node, you should look at both log files to determine which command failed and why it failed.
Problem Resolution:
If the NNodeSim.exe test fails you should look at all of log files. All variation and statistics gathering is done on the test client. However, error conditions such as I/O failures will be reported in the server log file.
Here is a list of the common problems this test has found:
1. Release command. This SCSI II command should never fail. Even if the initiator issuing the release currently doesn. t have a reservation. The semantics of this command is that after it completes the issuing initiator no longer owns a reservation.
2. No commands besides inquiry and request sense should work from an initiator, if another initiator currently has a reservation on a disk. This test will attempt to do write, read, and test unit ready commands that should fail in this scenario.
3. Write caching problems. If the controller or RAID device does any write caching it must guarantee the cache for both paths.
Phase 2 Testing . Validate 1 Node (24 hours)
Phase 2 of the testing will use the same HW configuration seen in figure 1. At this point you should install the cluster software on NodeA and NodeB server, one at a time, per the cluster installation instructions accompanying the operating system you are validating. This phase of the testing is to ensure that all of the cluster resources will work with only a single node up. This is an important case because in the event of failure users will expect their system to function just as if both nodes were up after a failure from NodeB, although with performance loss. For the Phase 2-5 tests a similar set of regression tests will be run. NodeB should be turned off during this part of the testing in order to simulate what would happen with a normal cluster node failure.
Phase 3 Testing . Validate Move Group 2 Node (12 hours)
Note: Optional Test.
Not required for cluster certification.
This test is run from a client master in the same manner as the Validate 2 Node test. When you start the Phase 3 testing you should turn NodeB on. This test will simply exercise the ability of the cluster and devices to handle continuous move group operations over a 24-hour period. A generic resource (lrgfile.exe) test will be run in each of the configured disk groups to simulate disk IO stress/activity on the cluster nodes during the move. In addition other tests that exercise SMB file sharing, Printing, IIS web and FTP may also be configured and run from client systems.
Phase 3 and phase 4 can be used to isolate the failures in case Phase 5 fails.
Phase 4 Testing . Validate Crash 2 Node (12 hours)
Note: Optional Test.
Not required for cluster certification.
This test is also run from a client master in the same manner as the Validate 2 Node Test (and the Move Group 2 Node Test). When you start the Phase 4 testing you should turn NodeB on. This test will exercise the ability of the cluster and devices to handle continuous reboots of the cluster nodes. A generic resource (lrgfile.exe) test will be run in each of the configured disk groups to simulate disk IO stress/activity on the cluster nodes during failover. In addition other tests that exercise SMB file sharing, Printing, IIS web and FTP may also be configured and run from client systems.
Phase 5 Testing . Validate 2 Node (24 hours)
The Phase 5 test runs with both nodes
powered on and joined into the cluster. When you start this test NodeB must be powered
on. The
test will utilize a minimum of 8 client machines to run client/server stress
tests against the cluster. While these client tests are running a
monitoring process (spfail.exe) will initiate asynchronous move group operations
mixed with rebooting cluster nodes. This will cause the resources on one node to
move between the nodes. The client tests are engineered to
tolerate interruptions of cluster services (such as SMB and IIS). The tests perform
re-try operations for a limited time interval. If the monitoring process spfail.exe detects
that the resource remains offline or unavailable for too long, the spfail
process signals a failure and causes the tests to halt. In addition the
validation test engine (valdclus) is also monitoring several critical processes,
such as spfail and the cluster service, and will halt testing if it detects a
failure condition (i.e. a total loss of cluster service on all nodes). In the case of a
failure the test will report and error and log why the test stopped.
If you wish to manually monitor the cluster system you can run cluadmin on the client monitoring system (i.e. the . client master. ). The Phase 5 test runs with both nodes powered on and joined into the cluster. When you start this test
Running Optional Tests in Validation testing (Phase 2-5)
In order to run the optional tests in the Validation testing, you need to install the dependent services on all the cluster nodes. Once the dependent services are installed you must then add the test to the run. You can do this at step 12 of the Step by Step instructions below. Please note is running optional test is not a requirement for a valid submission. Here is list of dependencies on various optional tests:
WINS_Clnt needs WINS service installed on Cluster nodes.
DHCP_Clnt needs DHCP service installed on Cluster nodes.
FTP_Clnt needs FTP service installed on Cluster nodes.
MSMQ_Clnt needs the MSDTC resource installed on the Cluster nodes. The MSMQ service installed on the domain controller, the Cluster nodes and on each of the eight clients.
Installing optional test components for DHCP or WINS
On each Windows 2000 Advanced or Datacenter Server cluster node go to: Start -> Settings -> Control Panel. Double click Add/Remove Programs. Click on the Add/Remove Windows Components button. Under the Windows Components Wizard scroll down to the Network Services, list item. Highlight the item and click on the Details button. Select the list item check boxes for Dynamic Host Configuration Protocol (DHCP) and/or for Windows Internet Name Service (WINS). Click on the OK button. Follow the directions for the rest of the prompts. You may need to assign a static IP address on each of the network interface cards on the cluster nodes for DHCP and WINS to work correctly.
Installing optional test components for FTP
The FTP service is not installed by default on Windows 2000. To Install it on each Windows 2000 Advanced or Datacenter Server, go to Start -> Settings -> Control Panel from the task bar. Double click on Add/Remove Programs. Click on Add/Remove Windows Components button. Under the Windows Components Wizard highlight the Internet Information Services(IIS) list item and click on the Details button. Select the list item check box for File Transfer Protocol(FTP) Server. Click on the OK button. Follow the directions for the rest of the prompts.
Installing optional test
components for MSMQ
Prior to running the MSMQ HCT test, MSMQ must be manually installed and configured in the lab environment. There are three types of installations to be completed: The domain controller installation, the cluster installation and the client installation. Perform the installation in the order indicated below in . specific installation details. :
For all installations:
· To install MSMQ go to: Start -> Settings -> Control Panel. Double click Add/Remove Programs. Click on the Add/Remove Windows Components button. Under the Windows Components Wizard click the Message Queuing Services check box. Click on the Next button and proceed through the setup, accepting the default settings.
· Do not select the . enable routing services. checkbox when installing MSMQ. (This is not a default selection.)
· Detailed help for installing and configuring MSMQ is available in the online W2K help. The steps below are configuration guidelines to accommodate the test environment. For all other issues, please consult the online help.
For the cluster and client installations:
·
You should not be prompted for W2K MSMQ server; it should be
auto detected.
If you are prompted, then either MSMQ is not installed on a properly
selected DC, or a configuration error has been made. This does not necessarily
block the MSMQ HCT test, but indicates a sub-optimum enterprise configuration
for the test. At the prompting dialog, you may type in the name of the DC on
which you installed MSMQ. Setup should proceed normally after that.
Specific installation details:
- The Domain Controller
This is the first installation that must be completed. The target DC must be selected carefully if there is more than one to choose from in the W2K enterprise. The DC must be:
· A Windows 2000 DC (RC3 or later)
· In the same domain as the test cluster and test client machines.
· In the same Active Directory site as the cluster and clients. In fact, before the MSMQ is installed on the DC, confirm that a subnet is defined that associates the IP addresses of the DC, cluster and clients with the same site.
· The DC must be configured to contain a copy of the global catalog.
If these steps are done correctly, the following MSMQ installations will auto-detect the DC, and the MSMQ HCT test will run smoothly.
Allow some time (~30 minutes) after this MSMQ installation before attempting the cluster and client installations. This is to allow for internal and intra-site replication of the MSMQ server objects.
To install MSMQ on the DC, perform the steps as noted above for . all installations..
- The Cluster
The cluster should be installed
next. There are five separate installations involved . one installation for each
node to cluster MSDTC, one installation for each cluster node MSMQ, and one for
the MSMQ cluster resource.
MSMQ requires that MSDTC be
clustered and the MSDTC resource online before the MSMQ cluster resource can be
created.
Perform the installations in
this order:
·
Clustering MSDTC
On each node of a working
cluster go to the command line and run the program: comclust.exe. This should create
the resource MSDTC and bring it online. By default this should show up in the .
Cluster Group. .
Use the console command:
cluster.exe res
to confirm this, or use the
cluster administrator application.
·
Initial MSMQ installations
On each node of the working
cluster, install MSMQ as noted above for . all installations..
·
Clustering MSMQ
In the cluster group that
contains the MSDTC resource, create the MSMQ resource manually with the steps
outlined in the online help topic: . To configure Message Queuing resources for
server clusters.
- The Clients
On
each test client, install MSMQ as noted above for . all installations..
Client Server Tests
All of
the client server tests will be used both in Phase 2 to Phase 5 of the MSCS
validation process.
These tests can be broken down in the following type of tests:
1. File
IO using a SMB File share
2. IIS
tests
3. Print
Spooler tests
These
tests are designed to simulate the most common cluster resources that users will
run on a clustered system. All of these tests will log their results to a
log file. The
tests should be run for the period defined by that particular phase. The tests run in an
infinite loop.
The machine should be shutdown after the allotted test time. The log files can
then be examined to see which tests pass and which tests failed during the test
run.
All of
the client/server tests will be run in conjunction on each client node. The client tests
will use the well-defined names to access the cluster resources. We have a graphical
interface from the HCT test kit that is used to setup all of the cluster
resources.
Setting up and running client/server tests
The
HCT test manager will setup cluster resources so client tests can attach to well
known cluster names.
When running our program to setup the resources the following information
will be needed:
1. Cluster Name
2. Static
IP addresses
From
this input the setup program from the HCT test manager will setup the following
cluster groups (if needed) and resources on the cluster.
The
cluster groups will look like this:

1. Cluster Group
·
Setup
by cluster setup and the HCT test manager
·
Contains 1 shared disks
·
Contains at least 1 IP address (supplied by user
when setting up resources)
·
Contains a file share for each disk which points to x:\
(where x: is the drive letter for 1st shared
disk)
·
Contains a network name for the IP address
·
Contains a IIS WWW root for IIS queries to files on x:\
·
Contains a Generic Application to run the lrgfile test on x:
locally
·
Contains a Print Spooler resource
2. Disk
Group 1
·
Setup
by cluster setup and the HCT test manager
·
Contains 1 shared disks
·
Contains at least 1 IP address (supplied by user
when setting up resources)
·
Contains a file share for each disk which points to y:\
(where y: is the drive letter for 2nd shared
disk)
·
Contains a network name for the IP address
·
Contains a IIS WWW root for IIS queries to files on y:\
·
Contains a Generic Application to run the lrgfile test on y:
locally
·
Contains a Print Spooler resource
If you
have setup of more than 2 Disks as cluster resources these groups will just look
like the Disk Groups above except the number will be Disk Group N-1 where N is
number of disks in the cluster. The number of groups that are used for
testing is dependent on the number of available disks and the number set in the
MaxResGrps: spin box.
You must supply one static IP address for each group. However addition
static IP addresses maybe required if the clients are accessible to the cluster
through multiple networks.
Support for additional networks is intended as a means of
distributing the stress load between multiple clients/networks and disks. This should allow
more thorough testing of larger systems by eliminating network bottlenecks when
several disks and many clients are used. In general the more disks used for testing the
more tests will be started on each of the clients.
Step by Step Instructions to setup cluster resources and start Phase 2 tests
NOTE:
You must install the cluster administrator on the monitoring system where you
are going to run the HCT test kit from. Previous versions of the HCT test kit shipped
with a clusapi.dll.
We no longer ship this dll. Instead installing cluster administrator will
put clusapi.dll in your path so we can load it. This will allow the HCT test kit to run on
various MSCS versions.
You should use the exact operating system CD used to install the cluster
nodes.
1. On the
client-monitoring node insert the HCT CD. Start the Test Launcher by running
hwtest.exe.
This will lead you though several prompts asking for information about
your hardware.
For the most part this information is redundant since the actual system
you are testing is the cluster, however you must answer these questions before
it will start the Test Manager. You should only have to answer these questions
once.
2. The
first dialog for the Test Manager will contain optional locations for the HCT
update directory as well as the source and destination of the test
binaries. By
default these will be set to the CD as the source and the C:\hct directory as
the destination.
Verify these locations and then press the OK button.
3. After
a short while, another window titled: . TestManager. should popup and it should show
up two tree windows titled . Available Tests. and . Selected Tests. . Click on
plus box for Cluster in . Available Tests. Window. Then again click on plus box
for Nodes.
4. Select
. Validate 1 Node Cluster. under the Nodes subtree in the . Available Tests.
tree.
5. Click
on the Add button.
6. Click
on the Start button.
This should start the . Validation Tests. process.
7. Type
in the cluster name into the . Cluster Name:. editbox. If you make a
mistake simply type over the name.
8. (Optional) Click on the Verify button. This will attempt to
connect with the cluster and query the node names. The cluster name and
the node names should show up in the list box. Please note for the single node validation
test only one node name, and the cluster name, should show up. If there is more
then a single node name, please check that one of the cluster one of the nodes
is powered off before continuing.
9. Type
in each client name and add the name to the list by using the Add button. If you make a
mistake select the client name you wish to remove and click on the Del
button. The
number of entered client names is displayed immediately to the right in the .
Num Clients:. field.
10. (Optional) The . Min Clients:. field can be edited to match
the . Num Clients:. field. This is so the test can be run with fewer
clients and still pass. Please note that a validation run for
submission must have at least eight clients.
11. (Optional) The length of a test run can also be configured
by editing the
. Run Test(hrs):. field. Please note that a validation run for
submission must be at least 24 hours long.
12. (Optional) Individual client tests can be removed from a
test run. To do
this click on the . Configure. tab. You may be prompted as mentioned below in
steps 15 and 16 for account/password info and static IP addresses. This is so that it
can configure the default parameters for each of the tests. Once it has
completed configuring the default parameters it will display a . Tests. list
view. At this
point you can the check boxes to select/deselect individual tests.
13. (Optional) Parameter combinations of a particular test can
also be removed.
Select the test name in the left hand pane by clicking on the name. In the right hand
pane is a list view with the parameter combinations the test will be run
under. Select
the row you wish to delete and click on the . Del. button. Clicking on the Scan
button will re-compute the parameters for all of the tests.
14. Click
on the Start button
15. At
this point a dialog titled . Specify Account Password. will appear. Enter the account
and password for the cluster administrator account. This will allow a
special monitoring service (qserv) to be installed and run in the desired
security context.
If the password/account information entered is incorrect there should be
a dialog indicating this, when this happens return to step 15.
16. A
dialog titled . Specify static IP Addresses. will now appear. The dialog
will request one IP address per disk resource per network visible to the
clients.
Use the combo dropdown box to specify which network the IP addresses are
for, then add the static IP address for that network by typing them into the
editbox and using the Add button. If you entered the wrong address select the
incorrect address and click on the Del button to remove it. Repeat this
operation for each network. Then click on the OK button when done.
After
step 14, the client master will install qserv and other needed test services and
files onto the cluster node. It then will proceed to do the same for each
client in the client list. When step 16 completes the tests will then be
started on each of the clients, on the nodes and then finally on the local
system (i.e. client master). When that is completed the valdclus process
will switch to the . Status. tab and start the clock. The tests will then
run for 24 hours.
After that period all of the client nodes will shut down the tests to
start Phase 3.
Instructions to setup cluster resources and start Phase 3, 4 and 5 tests
Please
refer to the Phase 2 test. The setup procedure is identical except:
·
On
step 3, elect . Validate Move Group 2 Node. , . Validate Crash 2 Node. or .
Validate 2 Node. respectively.
·
The
cluster/client names should default to the previously used values.
·
The
previous values of Min Clients, Run Time(Hrs) and the Selected tests are not
remembered and always default to 12 or 24 and all the available tests.
The
Cluster Name can be changed by simply typing a new name in the . Cluster Name:.
edit box, and optionally hitting the Verify button. The client names can be
changed using the Add/Del buttons. The Phase 3, and 4 tests run for 12
hours.
The Phase 5 test runs for 24 hours. For Phase III at a random time interval
resource groups will be moved back and forth between the different cluster
nodes. For
Phase IV alternate cluster nodes will be reset simulating a crash of the
system. For
Phase V both move and crash operations will be intermixed along with orderly
shutdowns of one of the nodes. After the total run time has elapsed the tests
will all be shutdown and the results will be summarized into a log file.
When the Start button is pressed, the client monitor will initiate the client/server tests on each of the client node(s) automatically. After the client tests are started they will be added to the list displayed in the . Validation Tests. process under the . Status. tab. As the tests are started . Generic Application. resource(s) will be created on the cluster. The . Generic Application. resource(s) will run a local lrgfile test against each of the shared disks. For the . Move Group 2 Node. , . Crash 2 Node. and . Validate 2 Node. test an additional test process . spfail.exe. will be started on the client monitoring system. This process will periodically do moves, shutdowns and crashes on one of the nodes in the cluster.
The
client tests are designed to constantly access the server and put stress on the
network and also the shared SCSI bus. The tests can handle a node crash while they
are running.
The tests will just resume whatever type of client/server IO they were
doing before the crash happened. These tests are designed to simulate what will
happen in a real cluster environment when you have hundreds of clients accessing
the cluster and a failure happens. These tests will be continually asking for
service from the cluster so they simulate many real world clients that only ask
for server services a small percentage of the time.
We
currently have 5 different client/server tests. So at least 10 test instances
will be started against the cluster from each client node.
When the client and failover tests are completed the client monitoring system will shutdown all of the tests and produce a summary log. This summary log is reported to the test manager. In addition each of the client nodes instances may also have a more detailed log file(s) for each test. At the moment no automatic means exists for gathering these logs.
Clicking the . Abort. button will stop any running tests, in
some cases this will also force a close of the window if a critical process
(spfail.exe) was stopped. Closing the window at any time will
abort the tests and initiate the clean up code. This will attempt to stop all the test
processes and delete all the test resources. This will also return the summary log
(vald1nod.log or vald2nod.log) to the test manager.
Troubleshooting the failures
Here
is list of common mistakes user makes while running HCT kit:
1. Entering Duplicate IP Addresses that are already in use.
2. Entering Wrong Password when user is prompted for the
password.
- Installing Windows 2000 Professional on Client master
machine.
- Entering wrong IP Address for the given subnet mask when
HCT prompts for IP Address.
- Installing different numbers of Network Interface cards on
cluster nodes.
- The
domain/user account, which is being used by HCT to do authentication, does not
have local administrative privilege on all client machines and cluster
nodes.
Interpreting the log
When
the Validate Cluster Tests exit a summary log (vald1nod.log or vald2nod.log)
should be generated. If all of the tests started successfully
the first part of the log will be a listing of the machines involved. It should look
something like this:
****
+VAR+INFO 0
: [<computer>] <type>: 1381 Service Pack 5, cpu:2, level:21164,
mem:63, page:112
<computer>: is the computer name of the system
<type>: is either client, node or local
cpu:
is the platform type ( 0 for x86, 2 for alpha)
level:
is the level of the chip ( 4, 5, 6 for x86 21064, 21164 for alpha)
mem:
is the amount of physical memory (in meg)
page:
is the max commit limit (in meg)
If the
test failed to complete there should be a line like this:
+VAR+SEV2 0 : Test stopped with XXX
minutes elapsed.
Where
XXX < the expected time. This should be next to another line
indicating the state the test was in when it exited.
+VAR+SEV2 1 : Tests did not
complete
Exiting while in state: <State> : <StateNum>
Possible states include:
Unknown: <StateNum> - this is an unmapped error the
<StateNum> indicates the value
Stopped:, Connect_Error, Start_Error Running and
Stop_Error:
-
test was aborted by the user while in this state.
Running_Error: - this likely indicates a failure in one of
the . critical. processes. This usually means that spfail.exe exited
unexpectedly.
But it could also mean that all instances of a critical node process
(clussvc etc) are not running on any of the cluster nodes.
Which
critical process failed is usually indicated a few lines above. For example if the
spfail.exe process exited then you. ll see the message:
+VAR+SEV2 0
: A critical process: spfail.exe has stopped on <client-master>
In
which case the next place to look is in the spfail.log for the error (see
debugging failover in this document).
Another possibility is that the cluster service
(clussvc.exe) or one of the critical test processes (such as qserv.exe or
spsrv.exe) is exited or unavailable on all cluster nodes. This usually happens
because one of the cluster nodes didn. t restart, or we lost network
communication.
If the
system freezes at the . black screen. (i.e. before boot option prompt) then you
most likely have a hardware/firmware bug. Normally these issues are found in the Phase 1
test. See the
phase 1 test above for more information.
If the
system hangs during reboot after the boot loader prompt, then you. ll most
likely need to hook up a debugger to find if the system is crashing. Consult the DDK
documents on how to setup a debugger, and kernel mode debugging in general.
If the
system reboots but the cluster service didn. t restart, then you need to examine
the cluster logs. See another part of this document
(section named . What to do if tests fail, but you think it is a test
bug?. ) on how to enable cluster logging.
If you
suspect a communication problem then additional debugging information can be
usually found in the qserv.log. The qserv.log is in the
%windir%\system32 directory on every system running qserv as a service. On the client master
the qserv.log is in the testbin directory with the rest of the logs. Communication
problems are usually due to a problem in the network configuration. Consult your site
network administrator.
If the
test ran to completion it is still possible for the test to fail if:
·
We
lost communication to one or more of client qserv processes or the local qserv
process.
·
We
lost communication with all of the node. s qserv processes.
·
We
started the test without sufficient client qserv processes, node qserv processes
or the local qserv process registered with valdclus.exe.
This
last point can be verified by counting the number of . qserv. processes of each
of the respective types. As well as counting the number of . clussvc.
processes.
There should be a list of the processes running at the time the test
exited in the log file. The list is in the form:
+VAR+INFO 2 :
<process>|<pid>|<mem>|<state>|<elapsed
time>|<computer>|<type>
File I/O Testing Using an File Share
Microsoft has rewritten some of the Windows NT file I/O tests so they can handle failovers while running I/O tests. This test requires that one of the shared drives be set up with both a file share and a network name. The file share allows mapping from a logical name to a physical partition; the network name allows clients to access the file share. All of this will be set up by the scripts when they are run from the client monitoring system.
Lrgfile Test
This test creates a large file and then reads backward and shrinks the file while checking read data.
Lrgfile uses unbuffered I/O only and retries on every file I/O operation.
The user will not be required to know the syntax of these test programs. The test launcher will start the test when it is run on each client node. If the cluster is set up using the well-known names that Microsoft provides, no further input will be required.
The Lrgfile program will run as a generic cluster
application on the server. This allows the tests to provide local heavy I/O
stress on the cluster as well as client I/O stress. This is helpful in ensuring
that the SCSI bus can handle failovers when large I/O operations are present on
the bus. Validation test runs two slightly different variations of LRGFILE: one
locally on cluster server node (as Generic Application resource) and one as a
client on client machine.
Problem resolution:
If LRGFILE test fails, look for LRGFILE.LOG log file. This file should contain error information and reason for failure. Since LRGFILE test is run with -Vn switch (leave n MB of free space on disk), common problem is that test did not start at all, because there was not enough space to start the test. LRGFILE retries 15 times with 1-second pause between retries before exiting with this error. Another common problem is disk media failure. Such a problem is reported as data corruption because expected data was not read from the disk. To eliminate that kind of error run LRGFILE test locally on server. You can find LRGFILE.EXE in your HCT\TESTBIN directory or on HCT CD. Copy it on server node and run command from WINDOWS NT console.
lrgfile -r10 -p32 -b8 -dX:
-r10 means run 10 times
-p32 means that LRGFILE will use 32*4 kB chunks of data for each write/read operation
-b8 means that LRGFILE will use 8 buffers for asynchronous write/read
-dX: replace X with suspected shared drive letter. Be sure that disk is online on the node that runs LRGFILE!
LRGFILE will grow temporary test until it consumes entire
available disk space, than shrinks file back while checking data. DO NOT
MOVE/FAILOVER DISK RESOURCE DURING THIS TEST. After LRGFILE finishes, look in
the log file LRGFILE.LOG (in the same directory LRGFILE.EXE was run from) and
search for data errors (e.g. Disk data error: Chunk#xpct 0x12, chunk#got 0x0,
Page#=0). If you see this error your disk failed and is unreliable. If your
disk passes this test, but does not pass node test with random moves/failovers,
it point to the cache problem. If both tests pass but client test does not it
points to the problem in redirector. Mostly, data was not written on the disk,
but was cached (usually on hardware level) and reported as saved at the time
prior to failover/move.
Most of other errors are either due to cluster service
/resource failure or network failure.
Mapfile Test
This file system test sets up memory-mapped files to the cluster. It then modifies a section of the mapped file, committing these changes to disk by flushing the file mapping. After the flush operation completes, the test will read the data back into memory and compare that the correct data was written to the disk. If a failover happens before the flush operation, all changes are discarded and the test restarts. If a failover happens while the test is in the verification phase, it will simply redo the verification.
Mapfile test requires 4 MB of space on tested drive. If there is not enough space, Mapfile exits. Another common problem is network failure or cluster service/resource failure. If test fails because of data corruption problem (read data differs from expected), the cause is not easy to determine. Mostly, data was not written on the disk, but was cached (usually on hardware level) and reported as saved at the time prior to failover/move. See LRGFILE Problem resolution paragraph how to eliminate disk-media problem.
IIS Testing
In the list of cluster groups, Microsoft created the IIS group. This group will contain a network name and a shared driver. As part of the server setup script, Microsoft will copy some HTML files to the shared drives. Microsoft has modified its IIS client tests to continually poll the IIS server for information. This test simulates what an Internet Explorer or other browser client would see by constantly accessing the IIS pages on the cluster. It will also retry in the case of errors being returned from the IIS server on the cluster. The test will perform operations to make sure that the IIS server is returning correct data from the shared drive.
This test will be totally automated and will connect to the IIS virtual root in each disk group using the network name. A virtual root is a mapping from an IIS alias to a physical location on a disk currently owned by an IIS server machine. A typical example would be http:\\WolfpackIIS\home mapped to I:\wwwroot\home.html, where WolfpackIIS is the network name and Home is the IIS alias or virtual root.
There will be two virtual roots for each disk group:
· WWW root
· FTP root (optional, it is setup only when FTP_Clnt is selected)
There will be specific files that clients will access for each virtual root. For the WWW root, Microsoft will copy HTML files from the client monitoring system to the server. For FTP roots, Microsoft will copy files to the server from the client-monitoring node.
Gqstress Test
This test is designed to do constant IIS queries against the virtual root set up in each disk group. The test will make sure that the virtual root is online. If the test is unable to access the root, it will retry the operation. The test will allow the root to be offline for a certain period of time. This is expected during failovers because the network name and IP address have to be moved to the other server. This test can simulate thousands of queries in a short time; it is designed to stress the IIS virtual roots. Each client will have one instance of this test doing queries against each IIS virtual root that is a WWW root.
Problem resolution:
The name of the log file is gqstress.log. A SEV2 error indicates a failure. It is normal to have time out as it happens during fail over. The most probable cause for the test failure is that IIS may not be started, crashed or security problems. Ensure that IIS is installed and running. Use the IIS Service Manager to check whether the IIS service is started. You can use Microsoft Internet Explorer to see if IIS is accessible from the client. If IIS is up and running, check if all the virtual roots that are created are up and running (you can do this from IIS Service manager).
Do the following from the client browser to check if the IIS, network connectivity & security are fine.
· Go to the IIS service manager & disable NT LM authentication (on the nodes). This is because gqstress does not support NT LM authentication.
· From the browser fetch http://clustername, http://nodename1, http://nodename2, http://netname1, http://netname2. All of them should fetch the default IIS home page.
·
If
172.31.224.44 is the static IP address used for a group. Then 172-31-224-44 will be
the name of the Cluster resource. Then you can fetch the gqstress.htm from the
browser as follows: http://172-31-224-44/w3svc_q/gqstress/gqstress.htm.
Ftpstress Test (optional test)
As part of the setup, Microsoft will copy some small test files to the shared disks. This test will use FTP transfers to move that file back and forth from the client nodes. In the case of a failure, it will redo the last operation. It will keep track of which files have been successfully transferred to the server, and then verify that those files are actually on the server.
The name of the log file is ftpcont.log. A . FAIL: Max time out. indicates a failure. The most probable cause for the test failure is that ftp server may not be started or crashed. Ensure that ftp service is installed, running and accessible. Use the IIS Service Manager to check whether the FTP service is started. You can use the ftp client program that comes with Windows 95 or NT to check if ftp service is accessible from the client.
Print Server Testing
For Printer Server Testing clients will spool print jobs to the print server, the print server will spool the jobs to the shared drive, and then the clients will check their print jobs. In the case of failover, the clients will check that their print jobs are still available when the print server moves to the other node.
Problem resolution:
For trouble shooting printing, here are some things to
check. This
should also be in the release notes:
Rolling upgrade:
If jobs are lost on a NT4 node fail over to a Win2000 node
(or the reverse), check the the Printer:Properties:Advanced:Enable advanced
printing features is turned off (this is on Win2000). On NT4, turn on
Printer:Properties:General:Print Processor:Always spool RAW datatype.
Missing Printers:
Verify that the correct print drivers are installed on each
node. Go to
each node (print folder:server properties:drivers and install the driver needed
by the printer.
You can do this locally or remotely.
Resource won't come online or jobs are missing on
failover:
Check that the spool directory (print folder:server
properties:advanced, Spool Folder) is set to a directory on the shared disk.
Ports are missing:
On Win2000, you need new port monitors. LprMon and the
Standard TCP/IP port monitor have been revised to support clustering. Other third party
monitors may not work unless they have been updated by the ISV.
WINS Testing (optional
test)
This test verifies that WINS is responding to client name registration, name queries and name releases. This test is binary - either the service is working or it. s not working.
Problem resolution:
If one of the tests fails it will indicate that WINS is not functioning properly. In this case the user should check to see if the WINS service has started or if it has failed over correctly. If WINS failed to start on a fail over or it failed to move to the other node there should be event log entries in the event log and there should also be entries in the cluster log that can bee looked at to determine why WINS failed.
DHCP Testing(optional test)
This test has been designed to test the DHCP server on a
cluster. It acts as a DHCP client discover-offer-request-ack/nak. The results
can be viewed on the Test UI or via the log file.
COM+ (MSDTC) Testing(optional test)
This test verifies the COM+ Distributed Transaction
Coordinator (DTC) by creating unique files (GUID-named) in a Working Directory
resident on the Quorum resource (shared fail-over) disk drive. During Test
operation these files are processed under the control of DTC. This processing is
two-fold. First, the files are created and loaded with test data. Second, these
files are located under DTC control and examined for correct content. The end
result of this processing is the complete elimination of all files from the Test
Working Directory. A non-empty Test Working Directory is a failure
condition.
Problem resolution:
The COM+ test is designed to verify DTC's ability to manage
data during fail-over conditions. Two principle areas of failure are both
indicated by the presence of files in the Test Working Directory. The first area
is a general DTC failure where DTC has lost track of the guid-named files being
created in the Test Working Directory. The second area is a data compare failure
where the data present in the guid-named files does not match that originating
from the DTC-controlled durable log system.
To determine the type of failure encountered it is first
important to be familiar with the naming convention used for the guid-named
files.
The naming convention used in these unique guid-named files
is as follows: <guid>.fill for files that are currently loading with data
records under the control of DTC and <guid> for files that are fully
loaded with data records.
The same data records written to these files are also
written to a durable 2-phase commit compatible log (the Compensating Resource
Manager (CRM) log). During DTC 2-Phase Commit (2PC) processing data records from
the guid-named files are compared field-by-field with those received from the
CRM durable log system. If an error in compare is found then the guid-named file
will remain in the Test Working Directory and the records received from the CRM
durable log system will then be written to a guid-named file of the same name
with the word COMPARE appended to it (<guid>.COMPARE). These file pairs
can then be examined by a hex editor (such as MS Visual Studio) to determine the
mismatched data. A compare failure is a serious problem and should be reported
to Microsoft.
If files not named with the COMPARE tag are present then
either DTC or the test client has lost track of the guid-named files being
created in the Test Working Directory. The most common cause of this kind of
indication is the client finishing its test requests to the cluster while the
cluster is failing over. If a failure indication is encountered with the COM+
test then it is important to re-run the test without fail over. This will allow
the final test to complete and clean up the Test Working Directory. Note that
this procedure will not clear up COMPARE errors.
If the preceding steps fail to resolve the failure indicated
then an examination of the Test configuration present on the cluster is in
order. Verify that the Test Working Directory and Test Install Directory are
present and valid (pointing to actual directories) on both cluster nodes. These
entries must be identical for both clusters for this test to perform properly.
The registry key to examine is HkeyLocalMachine\Microsoft\Software\CRMFT. Under
this key will be the Working and Install directories used by the COM+ test. As
previously mentioned these keys must be identical on both cluster nodes and
referencing valid directories on the quorum cluster resource.
If the test fails to start or if there are any problems
beyond that mentioned above please clear the NT event logs on the cluster
servers and the client systems involved with the tests and reboot these
systems. If the problem again appears please review the
messages recorded in the NT event logs for
information regarding any encountered problems. The NT event
logs are accessed form the NT desktop under the MyComputer Icon
(MyComputer->Manage->EventViewer).
Causing Cluster Failovers During Client-Server Tests
When running the client-server stress tests during Phase 4 and 5, the most important test case is to have is cluster nodes crashing asynchronously. This will simulate what a real-world server might encounter. When the client-server stress tests are running, Microsoft will be simulating many clients simultaneously accessing the server. The cluster must be able to lose one node with all of this client activity. The clients should not experience more than a 30-second delay for all of their resources coming available on the nonfailing node. To accomplish this, Microsoft will install a special service on both nodes of the cluster. Microsoft will also install a test program on the client-monitoring machine, which will communicate with the service on both nodes of the cluster.
This test will also verify that all cluster resources present when the test starts will be moved back and forth when the nodes crash. If this test finds any problems with the state of the cluster, it will cause both nodes of the cluster to break into the kernel debugger. Without this, it is almost impossible to debug problems with the state of cluster resources. The failover test will wait one hour between each reboot to crash the other node. This will allow a large amount of client I/O.
The failover test is designed to crash one node of a cluster and then the other node. It waits for the crashed node to reboot and then it crashes the next node. This means that the client programs can expect to have access to the cluster resources at all times, except when actual failovers are happening. This test ensures that the controller firmware and also the miniport driver for the controller don. t stall while rebooting when the other side has SCSI reservations on the shared drives. It allots time for each server to reboot after a crash. If the server fails to reboot within the allotted time, it registers a failure. This is how most Windows NT/Windows 2000 Server setups will work when the default is to have the node crashdump and then automatically reboot after a failure.
As part of Phase 4 and 5, Microsoft will set up this test on both servers and also on the client-monitoring node. No changes are needed to the other client nodes. This will install a new service and a special driver on each server in the cluster.
The client-monitoring node will log all information and print out its status on the kernel debugger for each server in case of problems. The log file on the client-monitoring node is called spfail.log.
The Crashtst test should be run during all of Phase 4 and 5. The number of reboots will depend upon how fast the machine reboots. If anything goes wrong or if the client node detects any inconsistent resource states on the cluster, it will cause each cluster node to enter the kernel debugger, and the test on the client node will stop. To analyze the problem, the log file generated by the Spfail.exe test can be analyzed along with the logs on the cluster nodes from the cluster service.
Failover Program
The
components of the failover program are Spfail.exe on the client monitor system,
spsrv.exe, remclus.dll and crashtst.sys on each node. Spsrvcl.exe is a client
program to spsrv is used to debug spsrv. Spfail.exe sends the crash command to
the spsrv. Spsrv after receiving the crash command, it passes the command to the
kernel mode device driver crashtst, which in turn calls the following HAL
routine HalReturnToFirmware to produce a node crash.
Interpreting the failover log
The
name of the logfile is spfail.log. Search for the . SEV2. from the beginning of
the log file. The first occurrence of the SEV2 error is the cause for the
failure of the spfail.exe. To get an explanation for an error code , use . net
helpmsg error-code. command. e.g.
C:\ >net helpmsg 1722
The RPC server is unavailable.
At
least one node should be up during the entire phase 4 and 5 testing. If both the
nodes die then spfail typically gets a 1722 error code (RPC Server unavailable
error).
Another typical reason why a spfail fails is if the node
fails to boot after the crash. In this case spfail.exe will time out.
Debugging common SPFAIL failures:-
Case 1:
0554.02AC 1999/11/07-00:07:45.502 +VAR+SEV2 963 :
MNSEM2N3(MNSEM2N3) is not restarted in 29 minutes Ping did not succeed
This means that the node MNSEM2N3 is not restarted after
after the crash. Check to see if the node is hung during the boot up. Most hangs
happen during the system bios initialization. This in most cases is a H/W
issue.
Case 2:
0354.0510 1999/11/04-03:30:40.762 +VAR+SEV2 59 :
WaitForGroupState: GetClusterGroupState returned ClusterGroupFailed
Group=Cluster Group Node=I2DELL1N1 GLE=5038 Retries=11
If you see a Group Failed with 5038 (or Timeout with 1460),
look for the actually resouce that is failed (or timed out).
0354.0510 1999/11/04-03:30:40.992 +VAR+INFO 60 :
Resource=MS Mail Connector Interchange Node:I2DELL1N1
Group:Cluster Group
Status:Failed
In this case the resource . MS Mail Connector Interchange.
failed. Now trouble shoot why did this resource failed.
Trouble shooting Failover
To
check if the spsrv is installed and functioning properly on each node run the
following commands from the client monitor.
.
spsrvcl . host:<node name> -cmd:ping. and
.
spsrvcl . host:<node name> -cmd:ping . input:crash.
Both
the above commands should return status=0 for success. Success of the first
command implies that spsrv is up and running. Success of the second command
implies that the spsrv did not load the remclus.dll which is a required
component to crash the node.
To
manually crash the node run the following command from the cmd window.
.
spsrvcl . host:<node name> -cmd:crash.
Simultaneous Reboot Test (optional, no logs required)
This test is not an automated test. However, Microsoft has found many problems with controllers and firmware when on a shared bus that this test was deemed necessary. The main objective is to make sure the controllers never hang during boot when both are turned on at the same time.
For this test, the system should be set up in the same fashion as for the crashtst test. As soon as both machines are booted, the cluster administrator tool should be used to make sure the shared drives can be moved back and forth to both nodes. Next, shut down both nodes and repeat the test. This should be performed 10 times to ensure that the boot works properly. No hang should be observed where one node hangs or has to be rebooted to get out of a hang. In simultaneous reboot of both nodes, it is acceptable as long as one node forms the cluster. If joining of the other node fails, please re-try joining and it should succeed.
How to Submit results to WHQL
To submit results you must have run all of the required tests. You will be required to submit 3 floppy disks or CD(s) or Zip Disk(s) with log sets on them. Here is the list of which log files should be on each disk that is required to submit the logs.
1. Phase 1 Server Log(s). This log file called NnodeSim_server.log has the output of the server side of the low level shared SCSI test. You need to enter all system information for the server that this test ran on.
2. Phase 1 Client Log. This log file called NNodesim_client.log has the output of the client side of the low level shared storage test. You need to enter all system information for the server that this test ran on. When you gather the results for the complete configuration testing you should list how you want your configuration listed on the HCL in the notes section.
3. Phase 2 and Phase 5 logs. These log files are generated on the monitoring node. The log files vald1nod.log and vald2nod.log will be put onto the diskette. You will need to fill in the system information on this node. However this information will only be of what was on the client node. The HCT test manager has no way to return log results without going through this process. All that is checked are the log results and not the actual monitoring node specifics.
What to do if tests fail, but you think it is a test bug.
We realize that in some cases you will run into a problem where you think it is a test bug that is blocking the tests from passing at 100%. Please go back and look in the troubleshooting section first. Failing that you can send the required log information to wolfhct@Microsoft.com so we can look at your problem. If we do determine that it is a test bug, we may allow your configuration to be listed. We believe that most test results of valid configurations should pass at 100% though. At a minimum the required log information sent to wolfhct@Microsoft.com should consist of:
The cluster logs for each node, the vald2nod.log (or vald1nod.log), spfail.log and the output from the following commands:
·
cluster.exe <node-name> res
·
cluster.exe <node-name> group
·
cluster.exe <node-name> node
To enable cluster logging use the system applet under the
control panel to create the system environment variable . ClusterLog. and set it
to the path of the log file to create.
Example: ClusterLog=C:\cluster.log
How to Return Log results
After running either the Phase 1, Phase 2 or Phase 3 tests you can go to the HCT Test manager and select return Cluster results. You will need a floppy disk for each of the 3 test machines involved. Please label the diskettes as follows
1) Cluster node #1 (should have Client/Server . Server test ran on it)
2) Cluster node #2 (should have Client/Server . Client test ran on it)
3) Monitoring Node (Should have vald1nod.log and vald2nod.log on it)
Cluster description on the HCL
We allow each vendor submitting a cluster configuration to pick the format of how it will be listed to some extent. No obvious marketing material may be included. Here is the general format that should be followed. This information should be listed in the Notes section when you are return the cluster logs for #2 above (client/Server . Client test).
Cluster Configuration Name
Server #1 name
Server #2 name
Shared Storage components (only Controllers SCSI or Fibre channel, Raid Controllers, or Raid devices should be listed. Don. t list drive cabinets, drives, cables, etc& ) NOTE: You must list the SCSI or FC controller you are using if you are using a HW Array device. If you are using a PCI based SCSI or FC Raid controller then you need only list that device.
Notes: any support information. You may also include a link to your own URL for further info.
Contact Information
Here is information on various email contacts in Microsoft.
If you
suspect the problem is a test bug, or if you have a technical question about the
test see the section below about sending problems to wolfhct@microsoft.com.
For information on submitting shared SCSI components for cluster candidate component validation, please see the web site at http://www.microsoft.com/hwtest/hwtest.htm. There is also an e-mail alias for questions about WHQL testing at whqlraid@microsoft.com.
All
other questions including result submissions should be directed to whqlclus@microsoft.com.